Reinforcement Learning with Python - Part 2
- Introduction
- Reinforcement Learning
- Finite Markov Decision Processes
- The Bellman equation
- The Q-algorithm
- Interface for the lake problem
Introduction problem
Winter is here. You and your friends were tossing around a frisbee at the park when you made a wild throw that left the frisbee out in the middle of the lake The water is mostly frozen, but there are a few holes where the ice has melted. If you step into one of those holes, you'll fall into the freezing water. At this time, there's an international frisbee shortage, so it's absolutely imperative that you navigate across the lake and retrieve the disc. However, the ice is slippery, so you won't always move in the direction you intend. The surface is described using a grid like the following:
- Black tile : the moving agent at the starting point, safe
- White tile : frozen surface, safe
- Red tiles : hole, fall to your doom
- Green tile : goal, where the frisbee is located
The episode ends when you reach the goal or fall in a hole. Consequently, you have to find a safe path
to find the frisbee in the lake. If possible, you have to find the shortest one.
Of course, we assume that the agent doesn't know where are the holes and the frisbee.
The agent receives a reward of $\mathbf{+1}$ if he reaches the goal, and zero otherwise.
We want to solve the previous problem by using a Reinforcement Learning methodology.
The Reinforcement Learning algorithm allows you to teach an agent to maximize his gains in an environment
where each action gives him a reward (positive or negative).
It's implement the “agent-environment loop”:
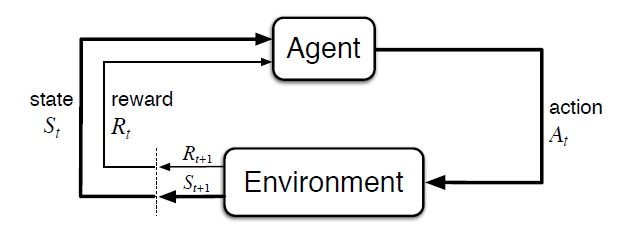
Each timestep, the agent chooses an action, and the environment returns an observation and a reward. The agent controls the movement of a character in a grid world. Some tiles of the grid are walkable, and others lead to the agent falling into the water (in red). Additionally, the movement direction of the agent is uncertain and only partially depends on the chosen direction. The agent is rewarded for finding a walkable path to a goal tile (in green).
Reinforcement Learning
Reinforcement learning (RL) is the subfield of machine learning concerned with decision making.
It studies how an agent can learn how to achieve goals in a complex, uncertain environment.
The environment can be deterministic or stochastic, hostile (chess game) or not (tetris game),
partially observable (mobile robotics), known or unknown to the decision-making agent.
D’après Sutton et Barto, l’apprentissage par renforcement désigne toute méthode adaptative permettant de résoudre un problème de décision
séquentielle. Le terme “adaptatif” signifie qu’on part d’une solution inefficace, et qu’elle est améliorée progressivement en fonction de l’expérience
de l’agent (ou des agents).
Reinforcement consists in finding:
- a sequence of actions which provide an optimal reward
- a strategy where sometimes one sacrifices his rewards to small rewards in the short term in order to obtain much better rewards in the long term
-
RL is very general, encompassing all problems that involve making a sequence of decisions: for example, controlling a robot’s motors so that it’s able to run and jump, making business decisions like pricing and inventory management, or playing video games and board games. RL can even be applied to supervised learning problems with sequential or structured outputs.
-
RL algorithms have started to achieve good results in many difficult environments. RL has a long history, but until recent advances in deep learning, it required lots of problem-specific engineering. DeepMind’s StarCraft II results and AlphaGo all used deep RL algorithms which did not make too many assumptions about their environment, and thus can be applied in other settings.
Finite Markov Decision Processes
At the beginning of the 20th century, the mathematician Andrey Markov studied the stochastic processes without memory, called Markov chains. Such a process has a fixed number of states and evolves randomly from one state to another at each stage. The probability that it goes from state $S$ to state $S'$ is fixed and depends only on the couple $(S, S')$ and not on past states. The system has no memory.
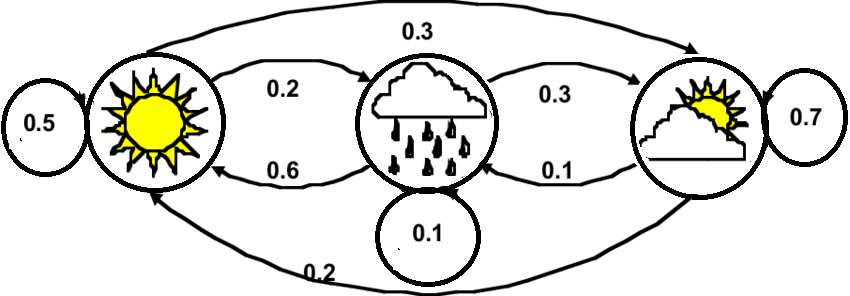
This Markov chain describes the probability of various weather patterns knowing the weather state. In the "sun" state the probability is of 50% for that state to stay like this. It is of 20% to pass to the "rain" state.
We introduce the formal problem of finite Markov decision processes, or finite MDPs.
They were firstly introduced by Richard Bellman in the 1950s.
They are very similar to Markov chains but at each
step, an agent can choose an action among several possible actions. The transition probabilities only depend from the chosen action.
In addition, certain transitions between states return a positive or negative reward.
The agent's goal is then to find a policy that maximizes the rewards over time.
We will use this strategy to solve the previous problem.
MDPs are a classical formalization of sequential decision making, where actions influence not just immediate rewards,
but also subsequent situations, or states, and through those future rewards. Thus MDPs involve delayed reward
and the need to tradeoff immediate and delayed reward.
MDPs are a mathematically idealized form of the reinforcement learning problem for which precise
theoretical statements can be made. We introduce key elements of the problem's mathematical structure,
such as returns, value functions, and Bellman equations.
MDPs are meant to be a straightforward framing of the problem of learning from interaction to achieve
a goal. The learner and decision maker is called the agent. The thing it interacts with, comprising
everything outside the agent, is called the environment. These interact continually, the agent selecting
actions and the environment responding to these actions and presenting new situations to the agent.
The environment also gives rise to rewards, special numerical values that the agent seeks to maximize
over time through its choice of actions.
More specifially, the agent and environment interact at each of a sequence of discrete time steps,
$t = 0,1,2,3,...$ At each time step $t$, the agent receives some representation of the environment's state,
$S[t]$, and on that basis selects an action, in $\{a_0,a_1,...,a_n\}$. One time step later, in part as a consequence of
its action, the agent receives a numerical reward, $r[t+1]$ and finds itself in a new state, $S[t+1]$.
The MDP and agent together thereby give rise to a sequence or trajectory.
In a finite MDP, the sets of states, actions, and rewards all have a finite number of
elements. In this case, the random variables $r[t]$ and $S[t]$ have well defined discrete probability distributions
dependent only on the preceding state and action.
In the following MDP Figure, there are $11$ states. The purpose of the agent is to wander around the grid to finally
reach the Diamond in state $S_{11}$. Under all circumstances, the agent should avoid the Fire grid in state $S_7$. Also there is a blocked grid,
in state $S_5$, it acts like a wall hence the agent cannot enter it.
The agent can take any one of these actions:
For example, from $S_0$ the agent can choose two actions: $a_0$ and $a_3$.
If he chooses action $a_0$, he has a probability of 100% to reach state $S_4$ without any reward.
We can imagine here, that he can have a probability of 90% to reach state $S_4$ and 10% to remain in the state $S_0$ even if he chooses action $a_0$.
At state $S_{10}$, if he chooses action $a_3$, he has a probability of 100% getting a reward of $\mathbf{+1}$. He then reaches the final state $S_{11}$.
Moreover, if he chooses action $a_0$ at state $S_3$, he has a probability of 100% getting a reward of $\mathbf{-1}$. In other cases, the reward is zero.
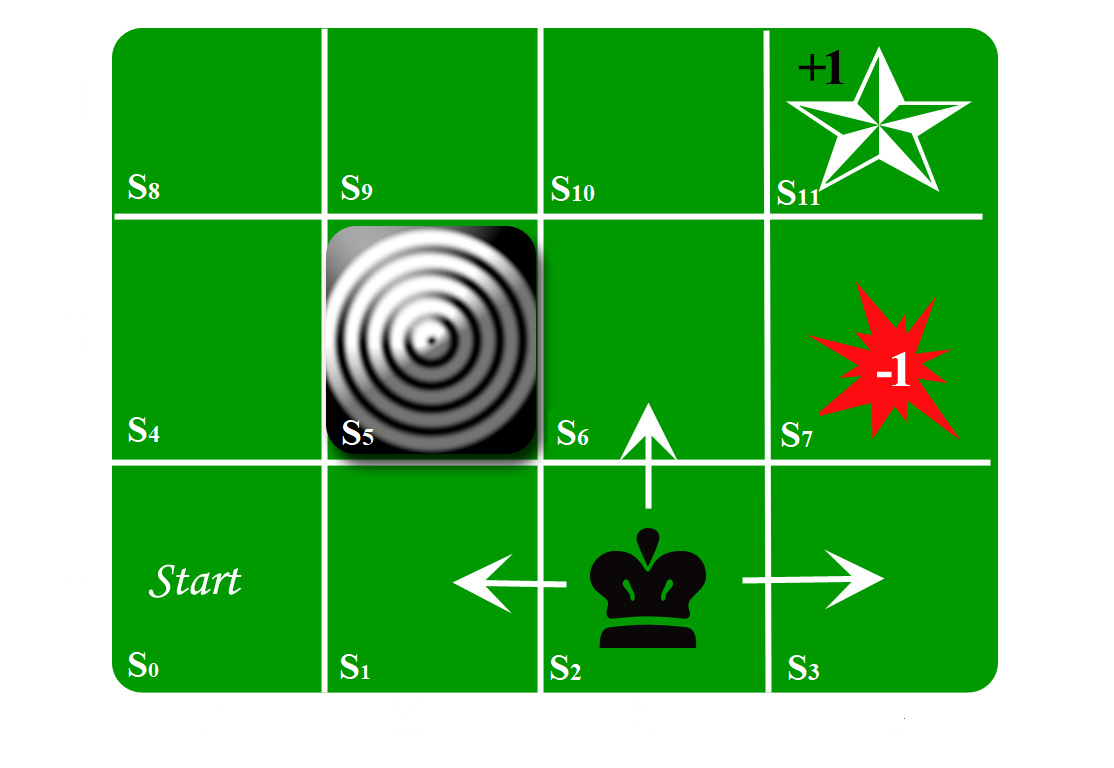
Let us give a state $S_i$, what is the strategy that will get the best reward over time?
The Bellman equation
In the following, we assume that the agent knows perfectly the MDP of the system. We will see in the Part 2, what kind of algorithms we can use when this is not the case. These algorithms are based on the Richard Bellman theory. We assume that we have $m+1$ different states. Richard Bellman has found a way to estimate the optimal state value of any state $S_i$, denoted by $V^*(S_i)$, which is the sum of all the rewards with future discounts that the agent can expect on average after reaching a state $S_i$, assuming that it acts optimally:
for all $i \in \{0,..,m\}:$ $$ V^*(S_i) = \max\limits_{a \in \{a_0,a_1,...,a_n\}} \sum_{j=0}^{m} \mathbb{P}(S_j | S_i,a)(r(S_i,a,S_j)+\gamma V^*(S_j)) $$where
-
$\mathbb{P}(S_j | S_i,a)$ is the transition probability from state $S_i$ to state $S_j$ knowing that the agent chose action $a$. For example, $\mathbb{P}(S_1| S_0,a_0) = 0.0$ and $\mathbb{P}(S_4| S_0,a_0) = 1.0$ in the previous MDP Figure.
-
Function $r(S_i,a,S_j)$ is the reward obtained by going from state $S_i$ to state $S_j$ by choosing action $a$. For example, $r(S_0,a_3,S_1)=0.0$, $r(S_{10},a_3,S_{11})=1.0$ and $r(S_{3},a_0,S_{7})=-1.0$.
- Coefficient $\gamma$ is the discount rate. It belongs to $[0,1]$. We will see the key role of this coefficient in the next exercices.
This equation is a necessary condition for optimality. It writes the value of a decision problem at a certain point in time in terms of the payoff from some initial choices and the value of the remaining decision problem that results from those initial choices. This breaks a dynamic optimization problem into a sequence of simpler subproblems. This recursive equation says that if the agent acts in an optimal way then the optimal value of the current state is equal to the reward which he will obtain on average after having carried out an optimal action, plus the optimal value expected for all the following possible states to which this action can lead.
This equation leads then us directly to the following algorithm which allows us to estimate the optimal values for each of these $m$ states. We intialize these values to zero and iteratively we adjust these values. For this we use the following iteration algorithm:
for all $i \in \{0,..,m\}:$ \[ V_{k+1}(S_i) = \max\limits_{a \in \{a_0,a_1,...,a_n\}} \sum_{j=0}^{m} \mathbb{P}(S_j | S_i,a)(r(S_i,a,S_j)+\gamma V_k(S_j)) \] where $V_{k}(S_i)$ for $i=0,...,m$ are the current estimated values for each states at the $k^{th}$ iteration. Obviously, the previous sum can be optimized by knowing which states are really linked to each states $S_i$. As we can see, each values are obtained from a fixed point algorithm. Exercise [Bellman Equation]In this exercice, we want to implement with Python this Bellamn equation estimation and apply it to the previous MDP Figure.
-
For this implementation, we need to define $\mathbb{P}(S_j | S_i,a)$ and $r(S_i,a,S_j)$. To do this, we create numpy arrays for these two functions. We assume that the value of $\mathbb{P}(S_j | S_i,a)$ will be given by using the numpy array P[i,a,j] where the indexes are ordered like this. You can use the numpy.full function to create an initial array with zeros. After that you can create an automatic algorithm that enables you to initialize all the probabilities. We assume here that the probability to do the given action is 100%.
-
Define the MDP class where:
- the attributes of the object with the numpy arrays P (transition probability array), r (the reward array), and a list of all possible actions of each states. For instance, $S_0$ has two possible actions and $S_1$ has three possible actions.
Consequently actions=[[0,3],[0,2,3],...].- the Bellman method which returns a list that contains the estimated optimal values for each states after niter iterations for a given $\gamma$ value ($\gamma$ and niter are parameters) We assume that $\gamma = 0.95$ and the maximum iterations number niter = 200.
class MDP(object): def __init__(self,P,r,actions): # To Do def Bellman(self, gamma =0.95, niter = 200): # To Do return V -
Create an object with the MDP class for the previous MDP problem, compare the results of the Bellman method with $\gamma=0.95$ and $\gamma=0.9$ for niter=200. Can you explain the differences? In fact, a reward (or payment) in the future is not worth quite as much as a reward now. For example, being promised 10000€ next year is worth only 90% as much as receiving 10000€ right now. Assuming payment $n$ steps in the future is worth only $0.9^n$ of payment now.
-
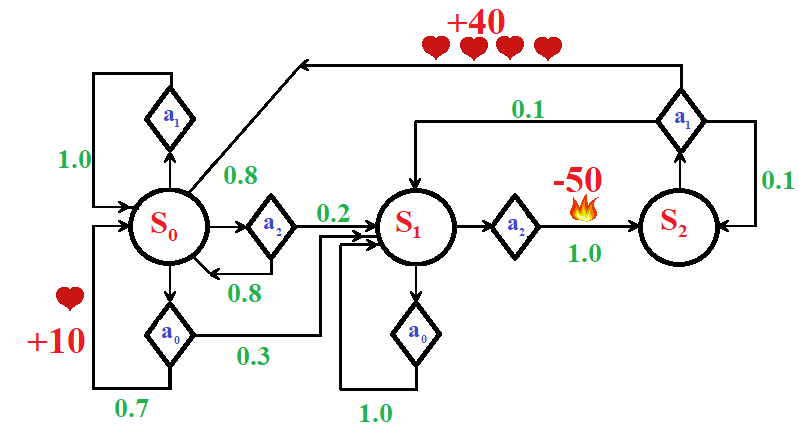
We assume now that we have the following MDP Figure:
m = 12
n = 4
P = np.full([m,n,m],0.0)
r = np.full([m,n,m],0.0)
for i in range(m):
for a in range(n):
for j in range(m):
if (a==0 and j == i + n) or (a==1 and j == i - n) or (a==2 and j == i - 1) or (a==3 and j == i + 1):
# Test to avoid to go to state S5 and S11 has no possible actions
if (i!=5 and j!=5 and i!=(m-1)):
P[i,a,j] = 1.0
r[3,0,7] = -1.0
r[6,3,7] = -1.0
r[11,1,7] = -1.0
r[7,0,11] = 1.0
r[10,3,11] = 1.0
class MDP(object):
def __init__(self,P,r,actions):
self.P = P
self.r = r
self.actions = actions
self.m = P.shape[0]
def Bellman(self,gamma = 0.95, niter = 200):
V0 = [0.0 for i in range(self.m)]
V1 = V0
for i in range(niter):
for s in range(self.m):
V1[s] = np.max([np.sum([self.P[s,a,sp]*(self.r[s,a,sp] + gamma * V0[sp]) for sp in range(self.m)]) for a in self.actions[s]])
V0 = V1
return V0
actions = []
for i in range(m):
temp = []
for a in range(n):
if (a==0 and i+4 < m) or (a==1 and i-4>=0) or (a==2 and (i%4-1)>=0) or (a==3 and (i%4+1)<=3):
temp.append(a)
actions.append(temp)
model = MDP(P,r,actions)
print(model.Bellman())
P = np.array([[[0.7,0.3,0.0],[1,0,0],[0.8,0.2,0]],[[0.0,1.0,0.0],[0,0,0],[0.,0.,1.0]],[[0.,0.,0.0],[0.8,0.1,0.1],[0.,0.,0]]]) r = np.array([[[10,0,0],[0,0,0],[0,0,0]],[[0,0,0],[0,0,0],[0,0,-50]],[[0,0,0],[40,0,0],[0,0,0]]]) actions = [[0,1,2],[0,2],[1]]
The Q-algorithm
As we can see in the previous exercice the Bellman equation only gives us the average optimal values for each states.
This not say to the agent what he has to do.
Which optimal action he as to choose at each states. For this, Richard Bellman designed a new equation called the Q-equation.
This leads to the Q-algorithm methodology. Q-algorithm is one of the technique to find the optimal policy in an MDP.
The objective of the Q-algorithm is to find a policy that is optimal in the sense that the expected value of the total reward over
all successive steps is the maximum achievable. So, in other words, the goal of Q-algorithm is to find the optimal policy by learning
the optimal Q-values for each state-action pair.
In the following, I give the Q-algorithm:
for all $i \in \{0,..,m\}$ and for all $l \in \{0,..,n\}:$
\[
Q_{k+1}(S_i,a_l) = \sum_{j=0}^{m} \mathbb{P}(S_j | S_i,a_l)(r(S_i,a_l,S_j)+\gamma \max\limits_{a \in \{a_0,a_1,...,a_n\}}Q_k(S_j,a))
\]
Consequently, as soon as we obtain the estimated of the optimal Q matrix, we can define the optimal policy $\pi^*(S_i)$ for each state i.e. the best action
to do at each state.
\[
\pi^*(S_i) = \underset{a \in \{a_0,a_1,...,a_n\}} {\text{argmax}} Q^*(S_i,a)
\]
Exercise [Q algorithm]
-
Implement this Q-algorithm. For this you will define a new function in the MDP class called Qalgo with $n$, $\gamma$ and niter as parameters. Parameter $n$ is the number of the possible actions.
def Qalgo(self, n, gamma =0.95, niter = 200): Q = np.full([self.m,self.m],0.0) # To Do return Q -
In order to obtain each optimal action for each state, you will apply the numpy.argmax(Q, axis =1) to the previous returned result. Show that the optimal actions for each state of the first MDP are:
$Q^*(s,a)$-Table $S_0$ 0.81450625 0 0 0.81450625 $S_1$ 0 0 0.77378094 0.857375 $S_2$ 0.9025 0 0.81450625 0.81450625 $S_3$ -0.05 0 0.857375 0 $S_4$ 0.857375 0.77378094 0 0 $S_5$ 0 0 0 0 $S_6$ 0.95 0.857375 0 -0.05 $S_7$ 1 0.81450625 0.9025 0 $S_8$ 0 0.81450625 0 0.9025 $S_9$ 0 0 0.857375 0.95 $S_{10}$ 0 0.9025 0.9025 1 $S_{11}$ 0 0 0 0
optimal actions for each states: [0 3 0 2 0 0 0 0 3 3 3 0]
class MDP(object):
def __init__(self,P,r,actions):
self.P = P
self.r = r
self.actions = actions
self.m = P.shape[0]
def Bellman(self,gamma = 0.95,niter = 200):
V0 = [0.0 for i in range(self.m)]
V1 = V0
for i in range(niter):
for s in range(self.m):
V1[s] = np.max([np.sum([self.P[s,a,sp]*(self.r[s,a,sp] + gamma * V0[s]) for sp in range(self.m)]) for a in self.actions[s]])
V0 = V1
return V0
def Qalgo(self,n,gamma = 0.95,niter = 200):
Q = np.full([self.m,n],0.0)
for i in range(niter):
Q1 = Q
for s in range(self.m):
for a in actions[s]:
Q[s,a] = np.sum([self.P[s,a,sp]*(self.r[s,a,sp] + gamma * np.max(Q1[sp])) for sp in range(self.m)])
return Q
model = MDP(P,r,actions)
print(model.Bellman())
res = model.Qalgo(4)
print(res)
print("Action optimale pour chaque état:")
print(np.argmax(res, axis =1))
Interface for the lake problem
To create the interface for the lake problem, solved by using the reinforcement strategy, we will use the tkinter module.
Exercise [tkinter interface class]
-
Create a class Game which enables:
For this you can use the following code which enables you to draw a square in a grid according to the mouse event coordinates.
- to initialize the size (pxp) of the graphical grid of the lake
- to allow to the user to define with the mouse all the holes (red tiles)
- to set the frisbee location (green tile)
- to create the MDP object for the RL resolutionfrom tkinter import * root = Tk() def key(event): print ("pressed", repr(event.char)) def callback(event): global dim canvas.focus_set() print ("clicked at", event.x, event.y) i=event.x//dim j=event.y//dim canvas.itemconfig(rectangles_array[i][j], fill='blue') canvas= Canvas(root, width=300, height=300) canvas.bind("< Key >", key) canvas.bind("< Button-1 >", callback) canvas.pack() rectangles_array=[] dim = 60 for i in range(5): raw=[] for j in range(5): if (i+j)%2==0: raw.append(canvas.create_rectangle(i*dim,j*dim, (i+1)*dim, (j+1)*dim, fill='green')) else : raw.append(canvas.create_rectangle(i*dim,j*dim, (i+1)*dim, (j+1)*dim, fill='red')) rectangles_array.append(raw) root.mainloop() -
Add to the class, a function path which "plays" the reinforcement strategy up to the agent finds the frisbee.
class TextBox(Entry):
def __init__(self,parent=None,width=30):
self.__text=StringVar()
super().__init__(parent,width=width, textvariable=self.__text)
def get(self):
return self.__text.get()
def set(self,text):
self.__text.set(text)
#classe d'interface pour la création et l'affichage du problème
class Game(Tk):
def __init__(self):
super().__init__()
self.sizeG=0 #taille de la grille carré
self.sizeC=30 #taille d'un carré en pixels
self.configureG=0 #numéro d'étape dans la configuration de la grille 0=arret, 1=point de départ, 2=point d'arrivée, 3=trous
self.depart=(0,0) #position du point de départ
self.arrivee=(0,0) #position du ooint d'arrivée
self.trous=[] #liste des positions des trous
self.rectangles_array=[] #liste les objets carrés de la grille
self.create_widgets()
self.MDPO=None #objet MDP pour la résolution
def create_widgets(self):
#création des cadres
#-----------------cadre11 de configuration de la grille --------------
# TO DO
#------------------ cadre12 de la résolution -------------------
# TO DO
#-------------------- cadre13 pour l'affichage des messages -------------------
# TO DO
#---------------- cadre2 pour l'affichage de la grille -------
self.cadre2=Frame(self, width=10, height=10, borderwidth=5,relief=GROOVE)
self.cadre2.pack(fill=X)
self.gride= Canvas(self.cadre2, width=self.sizeG*self.sizeC, height=self.sizeG*self.sizeC)
self.rectangles_array=[]
self.gride.bind("", self.callback)
self.gride.pack()
#gestion du click droit de la souris dans le canvas
def callback(self,event):
if self.configureG!=0:
#coordonnées de la souris dans la grille
j=event.x//self.sizeC
i=event.y//self.sizeC
if self.configureG==1:
#definition du point de départ
self.gride.itemconfig(self.rectangles_array[j][i], fill='blue')
self.configureG=2
self.depart=(i,j)
self.label1['text']="Choisir le point d'arrivée"
elif self.configureG==2:
#definition du point d arrivee
self.gride.itemconfig(self.rectangles_array[j][i], fill='green')
self.configureG=3
self.arrivee=(i,j)
self.label1['text']="Choisir les emplacements des trous\nCliquez sur le bouton pour terminer"
self.bouton_config['state'] = 'normal' #arret possible de la configuration
else:
#definition des trous
self.gride.itemconfig(self.rectangles_array[j][i], fill='red')
self.trous.append((i,j))
#mise en couleur d'une case de la grille
def colorize(self,j,i,color='black'):
#TO DO
#création de la grille
def creerG(self,size):
#TO DO
#configuration de la grille/ arret de la configuration
def configure(self):
if self.configureG!=0:
#arret
self.bouton_config.config(relief=RAISED)
self.bouton_config['text'] = 'Configurer la grille'
self.bouton_calcul['state'] = 'normal'
self.configureG=0
self.label1['text']=''
self.creerMDP()
else:
#démarrage de la configuration
v=self.texte1.get()
if v.isnumeric:
self.creerG(int(v))
self.bouton_config.config(relief=SUNKEN)
self.bouton_config['state'] = 'disable'
self.bouton_config['text'] = 'Fin de configuration'
self.bouton_calcul['state'] = 'disable'
self.configureG=1
self.trous=[]
self.label1['text']="Choisir le point de départ"
else:
self.label1['text']="la taille de la grille doit être un entier!"
#création de l'objet MDP en fonction de la configuration de la grille
def creerMDP(self):
#TO DO
#résolution du problème avec affichage du chemin
def path(self):
#TO DO
#Démarrage de l'interface
fenetre=Game()
fenetre.mainloop()
from tkinter import *
from tkinter.filedialog import askopenfilename
import numpy as np
#classe MDP pour la résolution du problème
class MDP(object):
#P : nparray de taille [m,n,m], avec m=nombre d'états et n=nombre d'actions
#P[i,a,j] contient la probabilité de passer de l'état i à l'état j par l'action a
#r: nparray de taille [m,n,m], avec m=nombre d'états et n=nombre d'actions
#r[i,a,j] contient la récompense de passer de l'état i à l'état j par l'action a
#actions : list de liste de taille[m],
#action[i] : contient la liste des actions possibles à partir de l'état i
def __init__(self,P,r,actions):
self.P = P
self.r = r
self.actions = actions
self.m = P.shape[0]
self.nb_action=P.shape[1]
#calcul de la valeur de l'état optimal pour chaque état par l'équation de Richard Bellman
def Bellman(self,gamma = 0.95,niter = 200):
V0 = [0.0 for i in range(self.m)]
V1 = V0
for i in range(niter):
for s in range(self.m):
V1[s] = np.max([np.sum([self.P[s,a,sp]*(self.r[s,a,sp] + gamma * V0[sp]) for sp in range(self.m)]) for a in self.actions[s]])
V0 = V1
return V0
#calcul de la valeur optimale pour chaque action à partir de chaque état
def Qalgo(self,gamma = 0.95,niter = 200):
Q = np.full([self.m,self.nb_action],0.0)
for i in range(niter):
Q1 = Q
for s in range(self.m):
for a in self.actions[s]:
Q[s,a] = np.sum([self.P[s,a,sp]*(self.r[s,a,sp] + gamma * np.max(Q1[sp])) for sp in range(self.m)])
return Q
class TextBox(Entry):
def __init__(self,parent=None,width=30):
self.__text=StringVar()
super().__init__(parent,width=width, textvariable=self.__text)
def get(self):
return self.__text.get()
def set(self,text):
self.__text.set(text)
#classe d'interface pour la création et l'affichage du problème
class Game(Tk):
def __init__(self):
super().__init__()
self.sizeG=0 #taille de la grille carré
self.sizeC=30 #taille d'un carré en pixels
self.configureG=0 #numéro d'étape dans la configuration de la grille 0=arret, 1=point de départ, 2=point d'arrivée, 3=trous
self.depart=(0,0) #position du point de départ
self.arrivee=(0,0) #position du ooint d'arrivée
self.trous=[] #liste des positions des trous
self.rectangles_array=[] #liste les objets carrés de la grille
self.create_widgets()
self.MDPO=None #objet MDP pour la résolution
def create_widgets(self):
#création des cadres
#-----------------cadre11 de configuration de la grille --------------
self.cadre11 = Frame(self, width=400, height=50, borderwidth=5)
self.cadre11.pack(fill=X)
self.label11 = Label(self.cadre11, text="taille de la grille carré :")
self.label11.pack(side=LEFT,padx=10,pady=10)
self.texte1 = TextBox(self.cadre11, width=30)
self.texte1.pack(side=LEFT,padx=10,pady=10)
self.texte1.set('10')
self.bouton_config =Button(self.cadre11, text="Configurer la grille", command=self.configure)
self.bouton_config.pack(side=LEFT,padx=10,pady=10)
#------------------ cadre12 de la résolution -------------------
self.cadre12 = Frame(self, width=400, height=50, borderwidth=5)
self.cadre12.pack(fill=X)
self.label2 = Label(self.cadre12, text="nonbre d'itérations :")
self.label2.pack(side=LEFT,padx=10,pady=10)
self.texte2 = TextBox(self.cadre12, width=30)
self.texte2.pack(side=LEFT,padx=10,pady=10)
self.texte2.set('100')
self.bouton_calcul =Button(self.cadre12, text="Calculer le chemin", command=self.path)
self.bouton_calcul.pack(side=LEFT,padx=10,pady=10)
self.bouton_calcul['state'] = 'disable'
#-------------------- cadre13 pour l'affichage des messages -------------------
self.cadre13 = Frame(self, width=400, height=50, borderwidth=5)
self.cadre13.pack(fill=X)
self.label1 = Label(self.cadre13, text="")
self.label1.pack(side=TOP,padx=10,pady=10)
#---------------- cadre2 pour l'affichage de la grille -------
self.cadre2=Frame(self, width=10, height=10, borderwidth=5,relief=GROOVE)
self.cadre2.pack(fill=X)
self.gride= Canvas(self.cadre2, width=self.sizeG*self.sizeC, height=self.sizeG*self.sizeC)
self.rectangles_array=[]
self.gride.bind("", self.callback)
self.gride.pack()
#gestion du click droit de la souris dans le canvas
def callback(self,event):
if self.configureG!=0:
#coordonnées de la souris dans la grille
j=event.x//self.sizeC
i=event.y//self.sizeC
if self.configureG==1:
#definition du point de départ
self.gride.itemconfig(self.rectangles_array[j][i], fill='blue')
self.configureG=2
self.depart=(i,j)
self.label1['text']="Choisir le point d'arrivée"
elif self.configureG==2:
#definition du point d arrivee
self.gride.itemconfig(self.rectangles_array[j][i], fill='green')
self.configureG=3
self.arrivee=(i,j)
self.label1['text']="Choisir les emplacements des trous\nCliquez sur le bouton pour terminer"
self.bouton_config['state'] = 'normal' #arret possible de la configuration
else:
#definition des trous
self.gride.itemconfig(self.rectangles_array[j][i], fill='red')
self.trous.append((i,j))
#mise en couleur d'une case de la grille
def colorize(self,j,i,color='black'):
self.gride.itemconfig(self.rectangles_array[j][i], fill=color)
#création de la grille
def creerG(self,size):
self.configureG=0
self.bouton_config.config(relief=RAISED)
self.label1['text']=''
self.sizeG=int(size)
self.gride.delete("all")
#mise à jour de la taille du canvas
self.gride.config( width=self.sizeG*self.sizeC, height=self.sizeG*self.sizeC)
self.rectangles_array=[]
#création des carrés de la grille
for i in range(self.sizeG):
raw=[]
for j in range(self.sizeG):
raw.append(self.gride.create_rectangle(i*self.sizeC,j*self.sizeC, (i+1)*self.sizeC, (j+1)*self.sizeC, fill='white'))
self.rectangles_array.append(raw)
#configuration de la grille/ arret de la configuration
def configure(self):
if self.configureG!=0:
#arret
self.bouton_config.config(relief=RAISED)
self.bouton_config['text'] = 'Configurer la grille'
self.bouton_calcul['state'] = 'normal'
self.configureG=0
self.label1['text']=''
self.creerMDP()
else:
#démarrage de la configuration
v=self.texte1.get()
if v.isnumeric:
self.creerG(int(v))
self.bouton_config.config(relief=SUNKEN)
self.bouton_config['state'] = 'disable'
self.bouton_config['text'] = 'Fin de configuration'
self.bouton_calcul['state'] = 'disable'
self.configureG=1
self.trous=[]
self.label1['text']="Choisir le point de départ"
else:
self.label1['text']="la taille de la grille doit être un entier!"
#création de l'objet MDP en fonction de la configuration de la grille
def creerMDP(self):
m = self.sizeG*self.sizeG
n = 4
P = np.full([m,n,m],0.0)
#initialisation de P
for i in range(m):
for a in range(n):
for j in range(m):
if (a==0 and j == i + self.sizeG) or (a==1 and j == i - self.sizeG) or (a==2 and j == i - 1) or (a==3 and j == i + 1):
#arrivée=etat final
if i!=self.arrivee[0]*self.sizeG+self.arrivee[1]:
P[i,a,j] = 1.0
#initialisation des actions
actions=[]
for i in range(m):
l=i//self.sizeG
c=i%self.sizeG
cactions=[]
if l< self.sizeG-1 : cactions.append(0)
if l>0 : cactions.append(1)
if c>0 : cactions.append(2)
if c< self.sizeG-1 : cactions.append(3)
actions.append(cactions)
# initalisation de r
r = np.full([m,n,m],0.0)
#récompensse point final
ind=self.arrivee[0]*self.sizeG+self.arrivee[1]
ind2=(self.arrivee[0]-1)*self.sizeG+self.arrivee[1]
if ind2 >=0 and ind2< m: r[ind2,0,ind]=1.0
ind2=(self.arrivee[0]+1)*self.sizeG+self.arrivee[1]
if ind2>=0 and ind2< m: r[ind2,1,ind]=1.0
ind2=self.arrivee[0]*self.sizeG+self.arrivee[1]+1
if ind2>=0 and ind2< m: r[ind2,2,ind]=1.0
ind2=self.arrivee[0]*self.sizeG+self.arrivee[1]-1
if ind2>=0 and ind2< m: r[ind2,3,ind]=1.0
#récompenses trous
for i in range(len(self.trous)):
ind=self.trous[i][0]*self.sizeG+self.trous[i][1]
ind2=(self.trous[i][0]-1)*self.sizeG+self.trous[i][1]
if ind2>=0 and ind2< m: r[ind2,0,ind]=-10.0
ind2=(self.trous[i][0]+1)*self.sizeG+self.trous[i][1]
if ind2>=0 and ind2< m: r[ind2,1,ind]=-10.0
ind2=self.trous[i][0]*self.sizeG+self.trous[i][1]+1
if ind2>=0 and ind2< m: r[ind2,2,ind]=-10.0
ind2=self.trous[i][0]*self.sizeG+self.trous[i][1]-1
if ind2>=0 and ind2< m: r[ind2,3,ind]=-10.0
self.MDPO=MDP(P,r,actions)
#résolution du problème avec affichage du chemin
def path(self):
niter=self.texte2.get()
if self.MDPO is not None and niter.isnumeric:
Q=self.MDPO.Qalgo(gamma = 0.95,niter = int(niter))
ind=self.depart[0]*self.sizeG+self.depart[1]
ind_final=self.arrivee[0]*self.sizeG+self.arrivee[1]
while ind!=ind_final:
action=np.argmax(Q[ind])
if Q[ind][action]>0:
if action==0: ind=ind+self.sizeG
if action==1: ind=ind-self.sizeG
if action==2: ind=ind-1
if action==3: ind=ind+1
if ind!=ind_final : self.colorize(ind%self.sizeG,ind//self.sizeG)
else:
raise Exception("chenmin bloqué!")
#Démarrage de l'interface
fenetre=Game()
fenetre.mainloop()
References
- R.S. Sutton, A.G. Barto (2017), Reinforcement Learning: An Introduction.
- R. Bellman (1957), A Markovian Decision Process